Appaction 论文阅读笔记
原文:https://dl.acm.org/doi/10.1145/3611643.3613885
美团技术报告:https://tech.meituan.com/2023/11/23/the-intent-of-ui-interaction-understanding.html
所有数据、表格、图像皆来源于上述两文
背景
当前商业移动 APP 具有前段技术栈多样(导致测试脚本难以泛用),组件样式多样(导致自动化组件识别困难),UI 定义代码迭代快(导致硬编码测试脚本经常需要维护)的特征。对于一类需要填写各种信息的页面(称为表单页面),不同的填写域对填写的内容格式有要求,交互间存在顺序依赖,使得随机交互的自动化测试方法表现不佳。
以上因素使得现有的移动 APP 测试泛用性/复用性差,自动化测试工具表现不佳,需要消耗大量人力,进一步导致难以在 APP 发布前对其进行充分测试。
实现
本工作推出了针对移动 APP 中的表单页面的自动化测试工具 Appaction,旨在模仿人工测试的“理解-交互-检查”的流程,通过利用 UI 渲染树、文本和图片三个模态对 UI 组件的意图进行识别,并据此与 UI 组件进行有意义的交互,提升人工测试效率。
Appaction 主要将 UI 组件从四个维度分类成不同交互意图簇,并根据分类结果进行自动化交互。
| 维度 | 类别 |
|---|---|
| 1. 业务层 | 顾客信息、商品信息、优惠、评价、备注、发票、提交按钮 |
| 2. 表单层 | 功能按钮、信息输入、标题、说明 |
| 3. 计算层 | 数量、金额统计信息 |
| 4. 操作层 | 点击、键入、长按 |
结合自动化测试和人类测试的特性,作者对 Appaction “理解”部分的整体架构进行了如下设计。
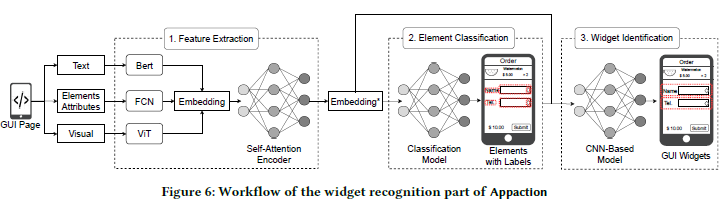
简单而言,Appaction 首先分析 UI 渲染树,对渲染节点中所包含的信息通过自注意力机制进行编码(1),然后利用得到的编码对节点进行分类(2),并将属于同一 UI 组件的节点聚类到一起(3)。
识别-第1, 2部分
Appaction 首先分析 UI 渲染树,将渲染节点特性、节点文本内容和节点图像分别进行嵌入、拼接,并通过自注意力机制进行编码,然后通过两层全连接层进行分类。这两个部分是一起训练的。
具体而言,渲染节点特性包括节点属性(例如 clickable,通常为布尔型)和一对坐标 (xyxy),这些特性被拼接成一个向量,然后送入一个一层全连接网络进行升维。节点文本内容被送入 Bert 进行编码,节点图像信息被送入 ViT 进行编码。三种信息的编码向量长度统一,进行相加后得到渲染节点的 Embedding 向量。
同一页面的所有节点的嵌入向量构成一个矩阵,通过自注意力机制进行编码得到 Embedding* 向量。这些向量进一步被送入一个两层全连接层进行分类。

识别-第3部分
一个 UI 组件通常由多个 UI 渲染节点组成。Appaction 利用渲染节点的 Embedding* 向量进一步进行聚类,将属于同一个组件的 UI 渲染节点聚类在一起,最终得到交互意图簇。
聚类器对渲染节点进行两两组合,判断节点是否属于同一类。实验中发现基于规则的/无监督聚类效果不佳,同时为了对齐人类偏好,聚类器训练采取了有监督训练方法。

交互
完成 UI 组件意图识别后,Appaction 根据识别结果和预定义的测试框架生成交互序列,并根据预定义的在不同类中要输入的内容填写表单。
实验
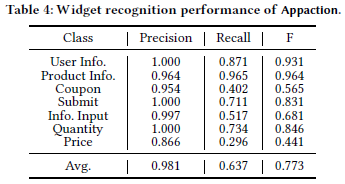
识别性能和消融实验
作者将工具的节点分类部分与 YOLOv7 进行了对比,并进行了消融实验。
训练集由美团 APP 四种业务线上随机截取的 158 张构成,人工标注后将其中的123张作为训练集。
| 模型 | 平均F1 Score | 顾客信息 | 商品信息 | 优惠 | 提交 | 信息输入 | 数量 | 金额统计 |
|---|---|---|---|---|---|---|---|---|
| YOLOv7 | 0.551 | 0.477 | 0.329 | 0.570 | 0.614 | 0.526 | 0.853 | 0.547 |
| 仅渲染树 | 0.779 | 0.816 | 0.794 | 0.700 | 0.863 | 0.784 | 0.785 | 0.686 |
| 仅图像 | 0.720 | 0.729 | 0.738 | 0.649 | 0.900 | 0.696 | 0.681 | 0.646 |
| 仅文本 | 0.780 | 0.905 | 0.798 | 0.733 | 0.734 | 0.789 | 0.737 | 0.823 |
| 图像+渲染树 | 0.813 | 0.833 | 0.783 | 0.740 | 0.926 | 0.795 | 0.839 | 0.754 |
| 文本+渲染树 | 0.837 | 0.920 | 0.813 | 0.758 | 0.865 | 0.797 | 0.922 | 0.815 |
| 图像+文本 | 0.830 | 0.916 | 0.788 | 0.788 | 0.924 | 0.776 | 0.826 | 0.829 |
| Appaction | 0.861 | 0.894 | 0.823 | 0.742 | 0.996 | 0.803 | 0.869 | 0.850 |
聚类性能借助兰德系数进行评估。
交互性能实验
作者从美团 APP 中选取了五条业务线进行测试,计算了交互成功的数量。
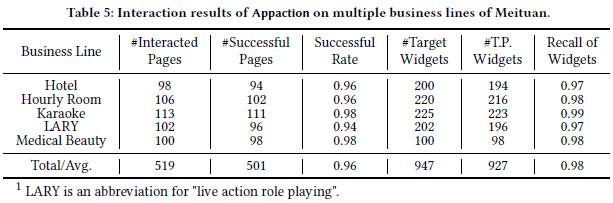
作者分析了失败原因,大多数是由于服务端的限制,例如一个用户只能下一个订单的业务逻辑限制。
作者还分析了 Appaciton 的识别速度,在 519 个页面上的平均速度为 4.1s/page
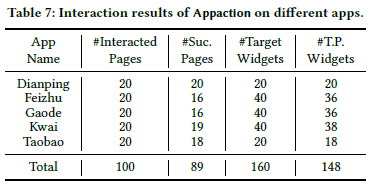
泛化性能实验
作者还测试了 Appaction 在其他几个商业 APP 上的性能。
Case Study
非功能性测试:避免陷入 Tarpits,提升页面覆盖率
对于非功能性测试(比如崩溃、卡死),随机测试工具通常已经足够。但是现代商业 APP 中到处都是表单,这类工具如果陷进表单(所谓 Tarpits,先把它叫一个“坑”吧)里,就很难再跳出来。结合 Appaction 填写表单,可以使随机自动化测试工具从坑里跳出来,从而提升覆盖率。
功能性测试:减少人力开销
利用 Appaction 对界面的意图识别能力,编写的测试脚本可以写得更简洁,也可以使测试动作对开发框架升级、或 UI 定义代码迭代更鲁棒,从而大大减少人力开销。
思考
解决问题的思路
感觉有两个思路可以借鉴。
一个就是经典的,梳理一个业务当前的流程,然后看看哪个局部是可以用一些方法来做提升。这个在美团的技术报告里面体现得更明显。
另一个就是模仿人类的思维。既然有些工作机器做不了但人类能做,那就不妨考虑一下人类是怎么做的,然后模仿人类的思维让机器来做这个事情

学术和业务的区别
总结这两篇文章的时候能很明显地感觉到,虽然这两篇文章讲的是同一个东西,但是搞学术跟搞业务的区别还是挺大的。
论文的行文是一个逻辑推理的流程,因为怎么怎么样,所以怎么怎么样。而且作为软工的论文(特别是工业轨),一些原理性的东西没有讲的那么细(反正大家都懂的)。
美团技术报告就不一样了,文章的行文整体上是由落地和应用在驱动的,更多讨论的是工具如何可以应用到业务中,工具是如何实现的。
