【论文阅读】OmniParser
原文:https://arxiv.org/abs/2408.00203
来自微软的工作,比较经典了,当初Orientor转投的时候也简单尝试过效果
任务
纯视觉驱动的UI屏幕解析工具,将UI截图解析为结构化的信息,促进下游UI自动化任务
动机
多模态大模型对UI截图及其中的控件呈现出了基础的理解能力。但是在UI自动化任务中:
-
action grounding有困难
-
GPT-4V难以给出操作的准确xy坐标
-
set-of-marks (SoM)提升了操作的健壮性,但是依赖于HTML解析以及准确的bbox识别,限制了应用范围
set-of-marks:在输入的截图上标记可交互控件
Seeing is Believing: Vision-driven Non-crash Functional Bug Detection for Mobile Apps](/2025/10/25/paper-journal-tse-LiuLCWCWWHW25) 工作中提及,可以用不同的标记(比如不同颜色)来标注具有不同属性的控件,但是需要在文字prompt中给模型提供解释
希望构建一个跨平台、跨应用的泛化方法
贡献
- 基于DOM解析构建了可交互区域检测数据集
- 构建了OmniParser,一个纯视觉驱动的UI截图解析方法,整合了多种微调模型
- 在ScreenSpot、Mind2Web、AITW数据集上证明了OmniParser方法的有效性
方法
3个component:可交互icon检测模型,icon描述模型,OCR模块
可交互区域检测
SoM输入给LLM,但控件标注信息来自于微调的icon检测模型
微调数据集来自100k个流行网页,通过DOM树提取控件bbox
UI控件描述
微调BLIP-v2模型,对控件进行描述
微调数据集为GPT-4o生成,构建了7k个icon-描述对
为什么不直接用LLM的能力进行描述?
原文:我们认为这一局限性源于GPT-4V在执行复合任务时的能力受限——它需要同时完成识别每个图标的语义信息与预测特定图标区域后续动作的双重任务。
既然LLM已经在工作流中,为什么不直接调用LLM,但是分开做?逻辑不是很通
可能的解释:保持效率、降低成本
验证
基于操作描述定位bbox的能力
自行构建SeeAssign数据集
操作和bbox配对
按每张图上的bbox数量分成三挡难度:easy(<10),medium(10-40),hard(>40)


LLM输出完全不结构化,好怪
ScreenSpot数据集
操作与bbox配对,跨平台
自行构建数据集的必要性?
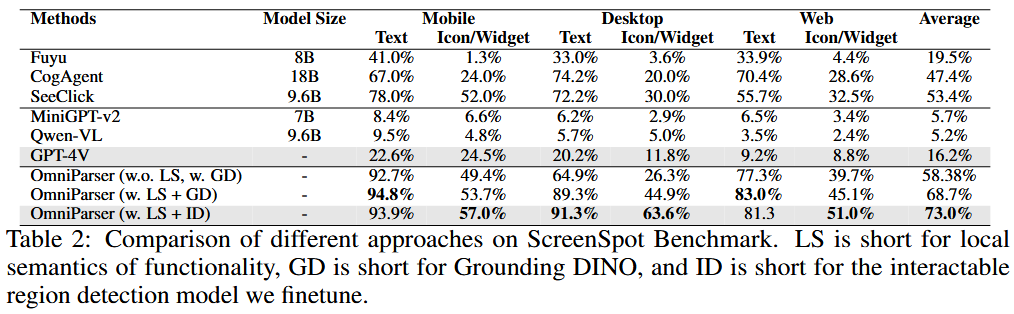
网页导航能力
Mind2Web数据集
3种类型的任务:跨领域,跨网页,跨任务
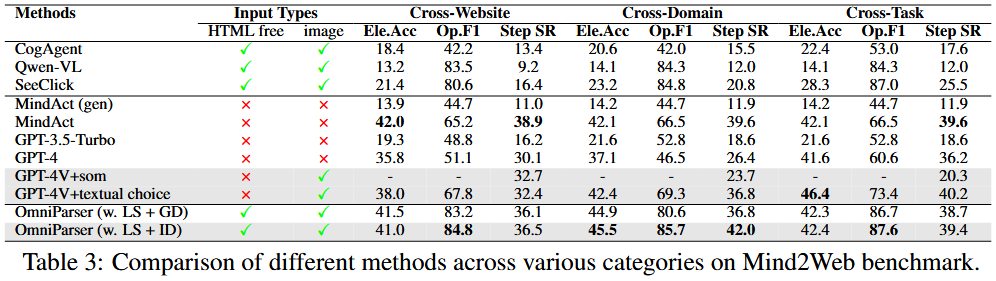
多步骤网页浏览能力
AITW数据集

发现icon detection模型具有泛化能力
讨论
failure cases
- 相同的icon和文本,模型容易定位到错误的instance上
- bbox粒度过粗
- icon理解错误:未能结合全局上下文信息
思考&启发
- 没有衡量描述的准确性(实际上也比较难衡量),而是基于下游任务进行评估
- 可以借鉴text-image的工作:BLIP/CLIP这些是怎么做的?
- 局部上下文信息太过有限,在原理上就无法处理重复的icon/文本,以及语义信息对上下文的依赖
