【论文阅读】VisionDroid多智能体UI自动化bug检测框架
原文:https://ieeexplore.ieee.org/document/11181197
最近回来做一些UI自动化相关的工作了,在狠狠地薅王俊杰老师组的羊毛
一个移动APP上的功能性Bug自动化检测框架VisionDroid
自动化探索、多智能体、视觉驱动
动机
- 由于缺乏明确的测试预言,现有的GUI测试方法难以有效检测功能性bug,多数局限在崩溃类bug上。
- 许多功能性bug会在GUI上有明显的表现,但通过GUI识别这些bug需要在GUI本身乃至GUI之间的转换上进行逻辑推理,同时需要一定的背景知识。现有的方法缺乏这样的能力。
3个挑战
-
视觉与文字模态输入的对齐
一方面,如果直接把图片塞给模型,MLLM可能会忽略很多细节;另一方面,MLLM的输出局限在文本模态,需要考虑如何将文本输出与GUI操作对齐
-
功能意图层面导向的应用探索
动作层面的信息对MLLM来讲太过细节且语义不够丰富,使其无法关注到功能层面的语义,需要理解动作对应的功能意图
-
测试预言推理
自动化应用探索检测功能性bug难以预先定义测试预言。
方法
VisionDroid由三个Agent组成,分别是视觉驱动的探索智能体Explorer,监控智能体Monitor和Bug检测智能体Detector
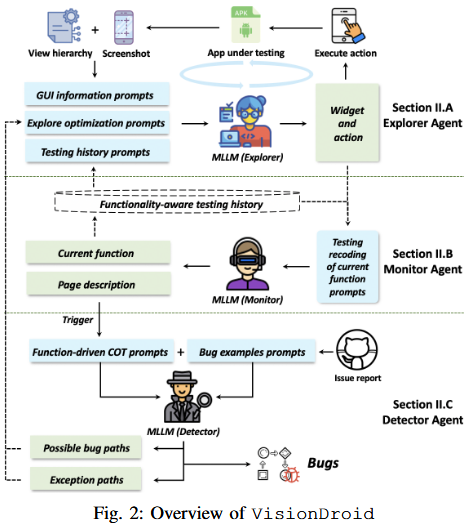
视觉驱动的探索智能体Explorer
负责基于APP信息执行实际探索
图像与文本模态对齐
通过图像标注,将控件与文本上线对应起来
文本上下文:
- 全局信息:从应用中获取App名字、Activity名字
- 控件信息:从UI层次树中文本、resource-id、交互方法
图像标注:
- 在UI截图上画框,通过不同颜色的框来标识控件交互方法
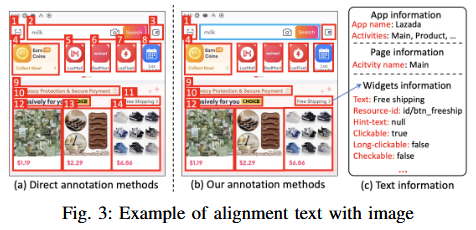
- 通过编号将控件与文本信息关联起来
这个用不同颜色表示交互方法的技巧值得参考。
- GUI控件的描述信息提取比较简单,没有对控件功能做进一步推理,功能理解直接交给MLLM隐式的推理了
- Activity名字、控件描述信息的提取依赖于代码,虽然可以用ADB工具获取,但是也算是灰盒甚至白盒测试了。不适用于游戏等纯黑盒场景,在现代APP的各种非原生开发技术栈上的泛化性也有疑问。
Prompting方法

文本模态输入:
- APP和GUI信息
- 历史操作信息
- 来自BugDetector的探索优化反馈
- 图像标记解释
图像模态输入:
- 历史操作及对应功能,截图中用不同颜色的框标记了操作的控件
- 当前页面,截图中用不同颜色的标记了所有可操作控件
要求输出:
- 动作指令(e.g. 点击/长按/勾选/滑动某一组件,输入文本以及输入文本后的操作)
这种将多个界面拼起来的历史信息提供方式很有意思,同时也能减少token量,值得参考
动作的目标是控件。界面滑动这种怎么算?没有说清楚。
监控智能体Monitor
负责
- 总揽测试过程
- 总结探索历史中的步骤
- 在合适的时候调用Detector检测Bug
操作历史记录
记录UI树、界面截图以及相关的操作,抽象出操作/GUI对应的应用功能。
在图像上以功能和对应截图的形式记录历史,截图中用不同颜色的框标记操作的控件
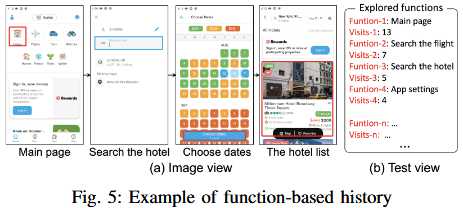
为避免Token超限而进行的信息压缩策略:
- 使用编号标识控件
- 只记录重要/信息量大的交互步骤
怎么界定某个步骤值得记录?没有说的很清楚
bugDetector触发
实时检测一个功能是否已经完成测试。如果已经完成,则暂停探索,调用Detector检查操作历史,检测此前测试的功能中是否存在bug。
如果bug发生在被过滤掉的交互步骤中呢?
Prompt方法

文本模态输入:
- 之前测试的功能和对应的动作
- 测试历史
- 图像标记解释
图像模态输入:
- 历史操作及对应功能,截图中用不同颜色的框标记了操作的控件
- 当前页面,截图中用不同颜色的标记了所有可操作控件
要求输出:
- GUI描述
- 描述当前正在测试的功能,同时检测现在是不是开始测试一个新功能了。
Bug检测智能体Detector
负责
- 检测执行序列中存在的逻辑问题
- 检测执行序列中存在的错误动作,给Explorer提供探索优化建议
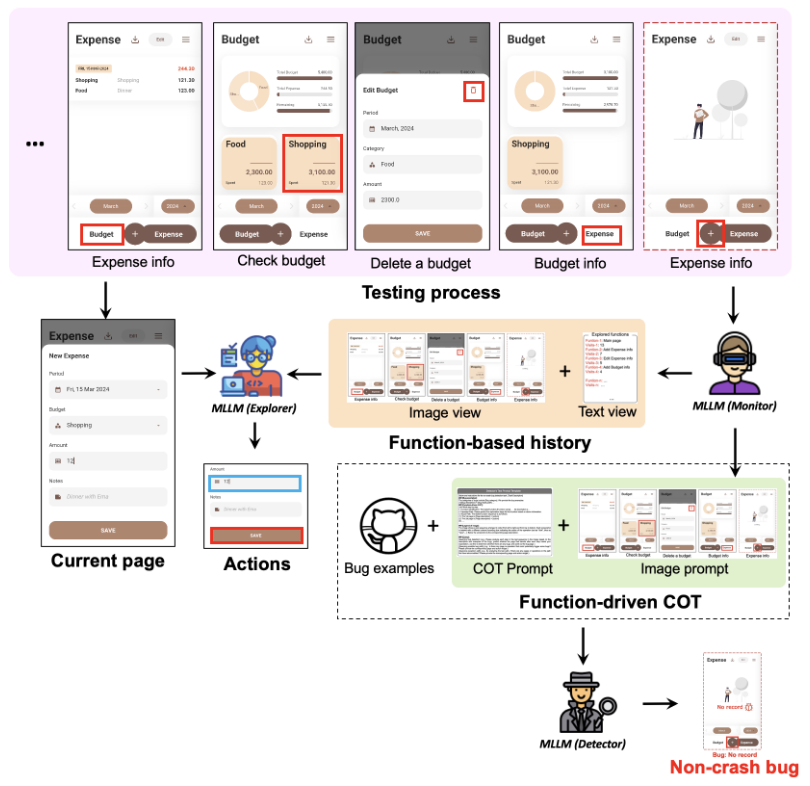
功能驱动的CoT
提示模型一步步分析,减轻幻觉影响
分析步骤:
- 识别当前正在测试的功能,输出功能名称和描述,帮助模型理解功能
- 分析期望操作路径:根据功能描述,推测期望的操作路径,作为评价基准
- 分析实际操作路径:检查实际进行操作路径,与期望路径做比对
ICL
利用开源移动app的issue构建样例数据库。
对于每个sample,结构化记录bug对应的功能、触发bug的操作序列、与期望行为的对比,帮助模型理解什么是功能性bug。
最终采集了200个高质量bug条目。
实验时,在数据库中排除待测APP,防止数据泄露
实践中,样例数据库可以动态扩充,新发现的bug经过人工检验后可以自动结构化并加入到数据库中。
通过比对Activity名字来检索样例,基于Word2Vec+余弦相似度检索。
Activity名字语义深度可能不太够,比较依赖开发者的命名习惯了,不过这个做法是follow之前的工作做的。
Prompt方法

文本模态输入:
- Bug示例
- CoT指令
- 图像标记解释
图像模态输入:
- 历史操作及对应功能,截图中用不同颜色的框标记了操作的控件
- 当前页面
要求输出:
- 应用截图变化序列是否符合预期
- 检测某个页面/某个操作会触发bug(反馈给Explorer)
- 检测Explorer做出的错误操作(反馈给Explorer)
流程示例
其他实现细节
采用GPT-4V作为MLLM
检索示例k=4(有超参实验)
实验
RQ
RQ1:覆盖率、bug检测性能
RQ2:消融实验
RQ3:实用性评估
指标
Activity覆盖率、代码覆盖率、报告的Bug数量、TP样本、Pre、Rec、F1
数据集
三个数据集:1)现有数据集(Odin,,RegDroid);2)基于Github Issue自行爬取的新数据集;3)Bug注入数据集。
构建数据集2的原因是现有数据集包含的app太老,bug类型太少,所以自行爬取了更多更新的数据。
构建数据集3的目的是防止数据泄漏,所以手动注入了一些bug。
自行构建的数据集可能有bias
结果
性能
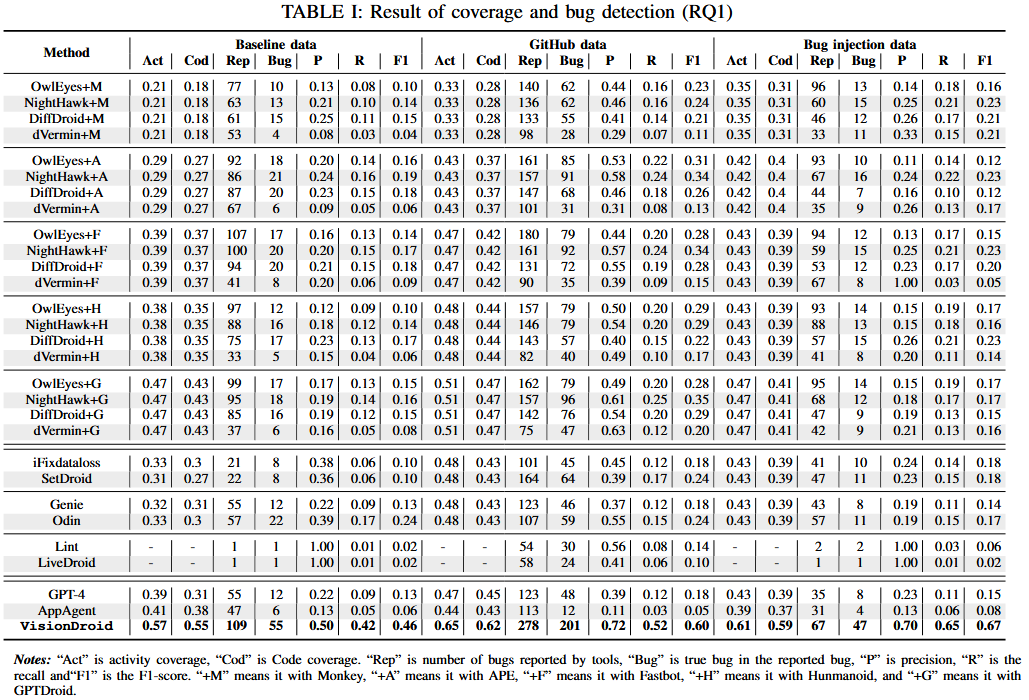
VisionDroid的所有指标显著高于Baseline(除了Pre低于两个静态工具,但是两个静态工具在高Pre的情况下Recall非常低)
最佳Baseline找到的bug是VisionDroid找到bug的子集
分析:
- 与baseline仅使用GUI树相比,VisionDroid加入了图像模态
- VisionDriod考虑了历史信息
- VisionDriod能够理解GUI序列的语义信息
Failure cases:
- 控件缺乏文本描述,MLLM难以理解控件语义
- 操作过程中界面有变化(控件ID、外观等,偶现的弹窗),造成历史信息失效
消融
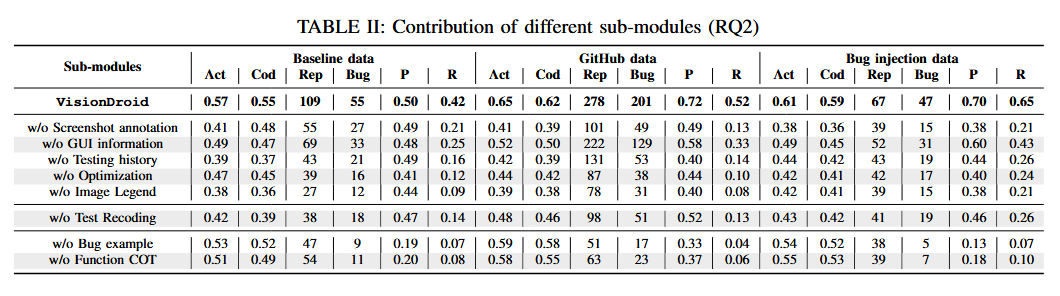
分析
- 没有CoT和ICL的Pre和Rec下降最明显,说明需要让模型理解什么是功能性bug,如何分析功能性bug
- 如果没有图像输入解释(输入布局、框含义等),模型难以理解标注的含义
实用性评估
在数据集的187个App上,VisionDroid从其中的74个App中检测到了102个功能性bug(仅7个FP),其中43个bug是此前未知的bug,31个已被修复,12个已被确认,并得到了开发者的高度认可。
思考&启发
-
GUI操作序列历史图像可以在一张图里拼接起来,既减少token使用,又能够将图像语义综合在一起,值得借鉴
-
将GUI输入到模型中时,可以添加标记来增强模型对GUI的理解,但一定要有对应的解释
-
RAG在自动化探索还是比较有必要的。要考虑如何将历史Bug、业务信息等融合到Prompt中。
-
文章依赖的输入信息比较浅表,控件的深层语义、基于Activity名字的检索等,有提升空间,可以探讨对控件语义做深层理解,利用语义更丰富的信息作为示例检索依据的提升。
文章也提到,控件中缺少文本信息时模型的表现比较差,此时是否可以进一步识别GUI组件的意图?
